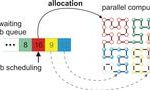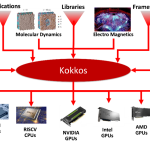

The Advanced Tri-lab Software Environment (ATSE) is an integrated software environment that provides a software ecosystem for leading-edge prototype high-performance computing (HPC) systems. By leveraging vendor software alongside open-source software throughout the stack, ATSE continually pushes forward the computing environment experience for the Advanced Simulation and Computing (ASC) program on next-generation systems.
Prototype systems often have gaps in the software available from vendors or from open-source development. The ATSE team works to provide a productive user environment in the early days of system availability by porting software and reference implementations, making upstream contributions, and working with vendors and open-source developers to provide deeply characterized bug reports. As the ecosystem around leading-edge systems continues to develop, ATSE integrates components from different sources and vendors to provide a complete experience to the ASC user. When possible, multiple sources for a software capability are provided to allow for experimentation and operational flexibility.
By concentrating on the software ecosystem challenges and opportunities presented by advanced architecture systems, prototype systems, and testbeds, ATSE aims to drive advancements in the breadth and effectiveness of computing systems available to ASC. This initiative not only enhances the overall performance and capabilities of HPC systems but also empowers vendors to add value within a cohesive and collaborative framework, ultimately fostering excellence in computational science and engineering.