
The CCR collaborates on innovations in tool development, component development, and scalable algorithm research with partners and customers around the world through open source projects. Current software projects focus on enabling technologies for scientific computing in areas such as machine learning, graph algorithms, cognitive modeling, visualization, optimization, large-scale multi-physics simulation, HPC miniapplications, HPC system simulation and HPC system software.
CIME
CIME
CIME is the Common Infrastructure for Modelling the Earth. It is the full-featured software engineering system for global Earth system or climate models. CIME is a set Python scripts configured with XML data files as well as Fortran soure code, and owns the model configuration, build system, test harness, test suites, portability to many specific HPC platforms, input data set management, results archiving.CIME is jointly developed by NCAR, Sandia, and Argonne, and is the software engineering system for several important climate/weather models: E3SM, CESM, and UFS.
Research Area
Contact
Compadre Toolkit
Compadre Toolkit
CrossSim
CrossSim
CrossSim is a GPU-accelerated, Python-based crossbar simulator designed to model analog in-memory computing for any application that relies on matrix operations. This includes neural networks, signal processing, solving linear systems, and many more. It is an accuracy simulator and co-design tool that was developed to address how analog hardware effects in resistive crossbars impact the quality of the algorithm solution.
CrossSim has a Numpy-like API that allows different algorithms to be built on resistive memory array building blocks. CrossSim cores can be used as drop-in replacements for Numpy in application code to emulate deployment on analog hardware. CrossSim also provides both Torch and Keras compatible implementations of many analog-compatible neural network layers including linear and convolutional layers.
CrossSim can model device and circuit non-idealities such as arbitrary programming errors, conductance drift, cycle-to-cycle read noise, and precision loss in analog-to-digital conversion (ADC). It also uses a fast, internal circuit simulator to model the effect of parasitic metal resistances on accuracy.
CrossSim also supports simulating systems with a wide range of data representation strategies including using multiple devices per value (i.e., weight bit slicing) and multiple approaches to representing negative numbers. Each of these components provides a modular interface to allow users to quickly implement models of new research ideas and explore the effects within the context of a larger applications.
Research Area
Contacts
Dakota
Dakota
Dakota: Optimization and Uncertainty Quantification Algorithms for Design Exploration and Simulation Credibility.
The Dakota toolkit provides a flexible, extensible interface between analysis codes and iterative systems analysis methods. Dakota contains algorithms for:
- optimization with gradient and nongradient-based methods;
- uncertainty quantification with sampling, reliability, stochastic expansion, and epistemic methods;
- parameter estimation with nonlinear least squares methods; and
- sensitivity/variance analysis with design of experiments and parameter study methods.
These capabilities may be used on their own or as components within advanced strategies such as hybrid optimization, surrogate-based optimization, mixed integer nonlinear programming, or optimization under uncertainty.
Research Area
Contact
E3SM
E3SM
E3SM is an Earth System Model being developed by the DOE Energy Exascale Earth System Model (E3SM) project. E3SM Version 1 was released in 2018. E3SM Version 2 was released in 2021. The E3SM atmosphere model runs with the spectral element dynamical core from HOMME, upgraded to include new aerosol and cloud physics and improved convection and treatment of the pressure gradient term, and a formulation for elevation classes to better handle atmosphere and land processes more realistically in the vicinity of topography. The E3SM Land Model (ALM) is based on Community Land Model (CLM) version 4.5 updated to include a full suite of new biochemistry and VIC hydrology and dynamic land units and extensions to couple to land ice sheets. The E3SM ocean, sea ice and land ice components are built on the MPAS framework.
Contact
Genten: Software for Generalized Tensor Decompositions
Genten: Software for Generalized Tensor Decompositions
Tensors, or multidimensional arrays, are a powerful mathematical means of describing multiway data. This software provides computational means for decomposing or approximating a given tensor in terms of smaller tensors of lower dimension, focusing on decomposition of large, sparse tensors. These techniques have applications in many scientific areas, including signal processing, linear algebra, computer vision, numerical analysis, data mining, graph analysis, neuroscience and more. The software is designed to take advantage of parallelism present in emerging computer architectures such has multi-core CPUs, many-core accelerators such as the Intel Xeon Phi, and computation-oriented GPUs to enable efficient processing of large tensors.
Contact
Jet Partitioner
Jet Partitioner
The Jet Partitioner is a parallel graph partitioner that runs on most CPU and GPU systems (via Kokkos, a required dependency).
Kokkos
Kokkos
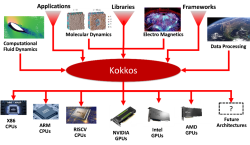
Modern high-performance computing (HPC) architectures have diverse and heterogeneous types of execution and memory resources. For applications and domain-specific libraries/languages to scale, port, and perform well on these architectures, their algorithms must be re-engineered for thread scalability and performance portability. The Kokkos programming system enables HPC applications and domain libraries to be implemented only once, while being performance portable across diverse architectures such as multicore CPUs, GPUs, and APUs.
This research, development, and deployment project advances the Kokkos programming system with new intra-node parallel algorithm abstractions, implements these abstractions in the Kokkos library, and supports applications’ and domain libraries’ effective use of Kokkos through consulting and tutorials.
Kokkos is an open-source project in the Linux Foundation, with the primary development support coming from Sandia National Laboratories, Oak Ridge National Laboratory, and the French Alternative Energies and Atomic Energy Commission.
Related Projects
Contact
Kokkos Kernels
Kokkos Kernels
Kokkos Kernels is a software library of linear algebra and graph algorithms used across many HPC applications to achieve best (not just good) performance on every architecture. The baseline version of this library is written using the Kokkos Core programming model for portability and good performance. The library has architecture-specific optimizations or uses vendor-specific versions of these mathematical algorithms where needed. This reduces the amount of architecture-specific software that an application team potentially needs to develop, thus further reducing their (modification cost)to achieve “best in class” performance.
Related Projects
Contact
LAMMPS
LAMMPS
LAPIS
LAPIS
Linear Algebra Performance through Intermediate Subprograms (LAPIS) is a compiler infrastructure based on MLIR for linear algebra that targets both high productivity and performance portability.
Related Projects
MALA
MALA

MALA is a software package for building and deploying Scientific Machine Learning Models for electronic structure calculations, specifically density functional theory (DFT) calculations. DFT is one of the most widely used methods for simulating materials at a quantum level and predicting their properties, employed by researchers worldwide. MALA is open source software developed by the Center for Computing Research at Sandia and CASUS.
Contact
ParaView
ParaView

ParaView is an open-source, multi-platform data analysis and visualization application. ParaView users can quickly build visualizations to analyze their data using qualitative and quantitative techniques. The data exploration can be done interactively in 3D or programmatically using ParaView’s batch processing capabilities.
ParaView was developed to analyze extremely large datasets using distributed memory computing resources. It can be run on supercomputers to analyze datasets of exascale size as well as on laptops for smaller data.
ParaView is maintained by Kitware, Inc. Sandia collaborates with Kitware to address our large-scale data analysis and visualization needs through ParaView.
Related Projects
Contact
Peridigm
Peridigm

Peridigm is an open-source computational peridynamics code. It is a massively-parallel simulation code for implicit and explicit multi-physics simulations centering on solid mechanics and material failure. Peridigm is a C++ code utilizing foundational software components from Sandia’s Trilinos project and is fully compatible with the Cubit mesh generator and Paraview visualization codes.
Research Area
Contact
Poblano Toolbox
Poblano Toolbox
Poblano is a Matlab toolbox of large-scale algorithms for unconstrained nonlinear optimization problems. The algorithms in Poblano require only first-order derivative information (e.g., gradients for scalar-valued objective functions), and therefore can scale to very large problems. The driving application for Poblano development has been tensor decompositions in data analysis applications (bibliometric analysis, social network analysis, chemometrics, etc.).
Poblano optimizers find local minimizers of scalar-valued objective functions taking vector inputs. The gradient (i.e., first derivative) of the objective function is required for all Poblano optimizers. The optimizers converge to a stationary point where the gradient is approximately zero. A line search satisfying the strong Wolfe conditions is used to guarantee global convergence of the Poblano optimizers. The optimization methods in Poblano include several nonlinear conjugate gradient methods (Fletcher-Reeves, Polak-Ribiere, Hestenes-Stiefel), a limited-memory quasi-Newton method using BFGS updates to approximate second-order derivative information, and a truncated Newton method using finite differences to approximate second-order derivative information.
Contact
Prove-It
Prove-It
Prove-It is a tool for proving and organizing general mathematical theorems using Python. Prove-It uses a flexible framework and a clear, concise presentation that appear like formulas one would present to colleagues on a chalkboard. Prove-It can avoid paradoxes by simply disallowing cycles in operator-operand relationships; this ensures that consistent types could be assigned but need not be assigned explicitly. Quantum algorithm verification is a particular target application.
Contact
PyApprox
PyApprox
PyApprox provides flexible and efficient tools for credible data-informed decision making. PyApprox implements methods addressing various issues surrounding high-dimensional parameter spaces and limited evaluations of expensive simulation models with the goal of facilitating simulation-aided knowledge discovery, prediction and design. Methods are available for: low-rank tensor-decomposition; Gaussian processes; polynomial chaos expansions; sparse-grids; risk-adverse regression; compressed sensing; Bayesian inference; push-forward based inference; optimal design of computer experiments for interpolation regression and compressed sensing; and risk-adverse optimal experimental design.
Contact
PyNucleus
PyNucleus
PyNucleus is a finite element code that specifically targets nonlocal operators of the form
$\int_{\mathbb{R}^d} [u(x)-u(y)] \gamma(x, y) dy $
for nonlocal kernels $\gamma$ with finite or infinite horizon and of integrable or fractional type. Specific examples of such operators include the integral and regional fractional Laplacians, their truncated and tempered variants, and operators arising from peridynamics.
The package aims to provide efficient discretization and assembly routines with $O(N \log N)$ quasi-optimal complexity. The resulting sets of equations can be solved using optimal linear solvers. The code is fully NumPy/SciPy compatible, allowing easy integration into application codes.
Contact
Pyomo
Pyomo

Pyomo is a Python-based open-source software package that supports a diverse set of capabilities for formulating, solving, and analyzing optimization models.
A core capability of Pyomo is modeling structured optimization applications. The Pyomo software package can be used to define general symbolic problems, create specific problem instances, and solve these instances using standard commercial and open-source solvers. Pyomo’s modeling objects are embedded within a full-featured high-level programming language with a rich set of supporting libraries that distinguishes it from other algebraic modeling languages such as AMPL, AIMMS and GAMS.
Pyomo supports a wide range of problem types, including:
- Linear programming
- Quadratic programming
- Nonlinear programming
- Mixed-integer linear programming
- Mixed-integer quadratic programming
- Mixed-integer nonlinear programming
- Mixed-integer stochastic programming
- Generalized disjunctive programming
- Differential algebraic equations
- Bilevel programming
- Mathematical programming with equilibrium constraints
Pyomo also supports iterative analysis and scripting within a full-featured programming language providing an effective framework for developing high-level optimization and analysis tools.
Contact
pyttb: Python Tensor Toolbox
pyttb: Python Tensor Toolbox
The Python Tensor Toolbox (pyttb) is a refactor of the Tensor Toolbox for MATLAB in Python. This package contains data classes and methods for manipulating dense, sparse, and structured tensors, along with algorithms for computing low-rank tensor decompositions. Tensors (also known as multidimensional arrays or N-way arrays) are used in a variety of applications ranging from chemometrics to network analysis.
Contact
Qthreads
Qthreads
The Qthreads API is a tool that helps developers easily manage many threads in their programs. It allows them to break their programs into smaller tasks and lets the system handle the scheduling of these tasks automatically. One of its features is the ability to mark each piece of memory as either “full” or “empty,” which helps threads wait for specific conditions to be met. This feature is useful for creating patterns where one part of a program produces data while another part consumes it, and it allows for more complex ways to synchronize these tasks.
Qthreads uses much less memory than traditional threads. Although developers interact with these threads as they would with operating system threads, they execute entirely in user space and use their status (locked or unlocked) to manage their scheduling.
Qthreads is the main tool for managing tasks in Hewlett Packard Enterprise’s runtime system for the Chapel parallel programming language. It also serves as a platform for researching and developing new system software techniques for advanced computer architectures.
Contact
Rapid Optimization Library (ROL)
Rapid Optimization Library (ROL)
Rapid Optimization Library (ROL) is a high-performance C++ library for numerical optimization. ROL brings an extensive collection of state-of-the-art optimization algorithms to virtually any application. Its programming interface supports any computational hardware, including heterogeneous many-core systems with digital and analog accelerators. ROL has been used with great success for optimal control, optimal design, inverse problems, image processing and mesh optimization, in application areas including geophysics, structural dynamics, fluid dynamics, electromagnetics, quantum computing, hypersonics and geospatial imaging.
Related Projects
Contact
Slycat
Slycat
Slycat™ is a web-based system for analysis of large, high-dimensional data, developed to provide a collaborative platform for remote analysis of data ensembles. An ensemble is a collection of data sets, typically produced through a series of related simulation runs. More generally, an ensemble is a set of samples, each consisting of the same set of variables, over a shared high-dimensional space describing a particular problem domain. Ensemble analysis is a form of meta-analysis that looks at the combined behaviors and features of a group of simulations in an effort to understand and describe the underlying domain space. For instance, sensitivity analysis uses ensembles to examine how simulation input parameters and simulation results are correlated. By looking at groups of runs as a whole, higher level patterns can be seen despite variations in the individual runs.
Contacts
SPARTA
SPARTA
SPPARKS
SPPARKS
Tracktable
Tracktable
Tracktable is a cross-platform library for analysis and visualization of the trajectories of moving objects. A moving object can be almost anything from a whale to an airplane to a cruise ship to the point on a screen where a user is looking. In other words, a moving object can be almost anything for which you have a unique ID and a series of coordinates with time stamps.
We include libraries for loading data from a variety of formats (principally CSV), assembling trajectories from timestamped points, and manipulating those trajectories mathematically. We also include a few pre-packaged analyses such as detecting co-traveling objects and identifying rendezvous.
Tracktable’s core is written in C++ for speed. The main interface to the toolkit is a set of Python bindings. Tracktable is available through PyPI (pip install tracktable) and the conda-forge channel for Anaconda.
In addition to the URLs below, our source code is available on GitHub at https://github.com/sandialabs/tracktable.
Trilinos
Trilinos
Contact
VisKores
VisKores
One of the biggest recent changes in high-performance computing is the increasing use of accelerators. Accelerators contain processing cores that independently are inferior to a core in a typical CPU, but these cores are replicated and grouped such that their aggregate execution provides a very high computation rate at a much lower power. Current and future CPU processors also require much more explicit parallelism. Each successive version of the hardware packs more cores into each processor, and technologies like hyperthreading and vector operations require even more parallel processing to leverage each core’s full potential.
VTK-m is a toolkit of scientific visualization algorithms for emerging processor architectures. VTK-m supports the fine-grained concurrency for data analysis and visualization algorithms required to drive extreme scale computing by providing abstract models for data and execution that can be applied to a variety of algorithms across many different processor architectures.
Related Projects
Contact
Zoltan
Zoltan
Zoltan is a toolkit of parallel algorithms for dynamic load balancing, geometric and hypergraph-based partitioning, graph coloring, matrix ordering, and distributed directories.
Zoltan is open-source software, distributed both as part of the Trilinos solver framework and as a stand-alone toolkit.