
The CCR enterprise is closely tied to the laboratories’ broader set of missions and strategies. We share responsibility within Sandia as stewards of important capabilities for the nation in high-strain-rate physics, scientific visualization, optimization, uncertainty quantification, scalable solvers, inverse methods, and computational materials. We also leverage our core technologies to execute projects through various partnerships, such as Cooperative Research and Development Agreements (CRADAs) and Strategic Partnerships, as well as partnerships with universities.
Advanced Memory Technology (AMT)
Advanced Memory Technology (AMT)

Under the Advanced Simulation and Computing (ASC) program, computer simulation capabilities are developed to analyze and predict the performance, safety, and reliability of nuclear weapons and to certify their functionality. Historically, the performance of many critical NNSA mission applications have been limited by memory bandwidth and latency. Memory bandwidth has increased at an order of magnitude less per year (on average) versus processor performance. Improving memory latency has proven to be even more challenging. Because of this, the ASC program seeks to inspire advancement in technologies that will dramatically improve effective memory performance for NNSA mission applications. The Advanced Memory Technology (AMT) program endeavors to collaborate with industry partners to drastically improve the state of the art in memory technologies and by extension the ability to accelerate the performance of ASC program mission applications.
Contact
Advanced Tri-lab Software Environment (ATSE)
Advanced Tri-lab Software Environment (ATSE)

The Advanced Tri-lab Software Environment (ATSE) is an integrated software environment that provides a software ecosystem for leading-edge prototype high-performance computing (HPC) systems. By leveraging vendor software alongside open-source software throughout the stack, ATSE continually pushes forward the computing environment experience for the Advanced Simulation and Computing (ASC) program on next-generation systems.
Prototype systems often have gaps in the software available from vendors or from open-source development. The ATSE team works to provide a productive user environment in the early days of system availability by porting software and reference implementations, making upstream contributions, and working with vendors and open-source developers to provide deeply characterized bug reports. As the ecosystem around leading-edge systems continues to develop, ATSE integrates components from different sources and vendors to provide a complete experience to the ASC user. When possible, multiple sources for a software capability are provided to allow for experimentation and operational flexibility.
By concentrating on the software ecosystem challenges and opportunities presented by advanced architecture systems, prototype systems, and testbeds, ATSE aims to drive advancements in the breadth and effectiveness of computing systems available to ASC. This initiative not only enhances the overall performance and capabilities of HPC systems but also empowers vendors to add value within a cohesive and collaborative framework, ultimately fostering excellence in computational science and engineering.
AGILE
AGILE

The AGILE program aims to achieve significant performance advancements for large-scale data-analytic applications, as well as other classes of data intensive applications. The program seeks to develop new, innovative, energy-efficient, and reliable computer architectures. A fundamental challenge in today’s computer systems is that they struggle to efficiently handle sparse and changing data that is randomly distributed across the system. The AGILE program looks to solve this problem by developing new system-level intelligent mechanisms for accessing, moving, and storing complex data to enable efficient data-analytics algorithms.
New computer architectures developed under the AGILE program are driven by the needs of real-world data-intensive applications. This design process, called co-design, means that the needs of the application shape the computer architecture, and vice versa. The designs focus on optimizing the system as an integrated whole, rather than improving individual parts independently (e.g., memory, computation, or communication). Importantly, designs are not limited by existing interfaces and protocols, legacy architectures, or current practices.
Contact
Albany
Albany

Albany is an implicit, unstructured grid, finite element code for the solution and analysis of partial differential equations. Albany is the main demonstration application of the AgileComponents software development strategy at Sandia. It is a PDE code that strives to be built almost entirely from functionality contained within reusable libraries (such as Trilinos/STK/Dakota/PUMI). Albany plays a large role in demonstrating and maturing functionality of new libraries, and also in the interfaces and interoperability between these libraries. It also serves to expose gaps in our coverage of capabilities and interface design.
In addition to the component-based code design strategy, Albany also attempts to showcase the concept of Analysis Beyond Simulation, where an application code is developed up from for a design and analysis mission. All Albany applications are born with the ability to perform sensitivity analysis, stability analysis, optimization, and uncertainty quantification, with a clean interfaces for exposing design parameters for manipulation by analysis algorithms.
Albany also attempts to be a model for software engineering tools and processes, so that new research codes can adopt the Albany infrastructure as a good starting point. This effort involves a close collaboration with the 1400 SEMS team.
The Albany code base is host to several application projects, notably:
- LCM (Laboratory for Computational Mechanics) [PI J. Ostien]: A platform for research in finite deformation mechanics, including algorithms for failure and fracture modeling, discretizations, implicit solution algorithms, advanced material models, coupling to particle-based methods, and efficient implementations on new architectures.
- QCAD (Quantum Computer Aided Design) [PI Nielsen]: A code to aid in the design of quantum dots from built in doped silicon devices. QCAD solves the coupled Schoedinger-Poisson system. When wrapped in Dakota, optimal operating conditions can be found.
- FELIX (Finite Element for Land Ice eXperiments) [PI Salinger]: This application solves variants of a nonlinear Stokes flow for simulating the evolution of Ice Sheets. In particular, it conducts climate modeling of the Greenland and Antarctic Ice Sheets for Sea-Level Rise. Will be linked into ACME.
- Aeras [PI Spotz]: A component-based approach to atmospheric modeling, where advanced analysis algorithms and design for efficient code on new architectures are built into the code.
In addition, Albany is used as a platform for algorithmic research:
- FASTMath SciDAC project: We are developing a capability for adaptive mesh refinement within an unstructured grid application, in collaboration with Mark Shephard’s group at the SCOREC center at RPI.
- Embedded UQ: Research into embedded UQ algorithms led by Eric Phipps often uses Albany as a demonstration platform.
- Performance Portable Kernels for new architectures: Albany is serving as a research vehicle for programming finite element assembly kernels using the Trilinos/Kokkos programming model and library.
Alegra
Alegra
The ALEGRA application is targeted at the simulation of high strain rate, magnetohydrodynamic, electromechanic and high energy density physics phenomena for the U.S. defense and energy programs. Research and development in advanced methods, including code frameworks, large scale inline meshing, multiscale lagrangian hydrodynamics, resistive magnetohydrodynamic methods, material interface reconstruction, and code verification and validation, keeps the software on the cutting edge of high performance computing.
ASCEND
ASCEND

ASCEND (Applied mathematics and Scientific Computing Ecosystem for the New Digital era) is a portfolio of projects funding by the DOE, Office of Science, Advanced Scientific Computing Research (ASCR) program, that consists of research and development in computational and applied mathematics seeking to address foundational research gaps in the digital twin ecosystem. Breakthroughs are needed to realize this new digital era. The ASCEND vision is to lay the mathematical and computational foundations that address research challenges and deliver breakthroughs in the following areas: high-fidelity forward models that encompass unprecedented time/length scales and physics complexity, algorithms to push beyond forward simulation that are scalable and risk-informed, and methods that can leverage modern heterogeneous scientific computing architectures. We accomplish this through a regional partnership between the three principal research institutions in New Mexico: Sandia and Los Alamos National Laboratories, and the University of New Mexico.
The ASCEND portfolio consists of five research thrusts in applied mathematics: advanced discretizations and linear solvers, multiscale and multiphysics methods, optimization, uncertainty quantification, and randomized algorithms and tensors. The research is motivated by fundamental challenges in modeling digital twins and focuses on a broadly-scoped exemplar that is of fundamental importance to the DOE: fusion/plasma physics. The ASCEND vision includes building the workforce of the future that is diverse and equipped with the interdisciplinary skills to meet our research challenges. We will leverage our geographic proximity to promote close collaboration.
Contact
CHaRMNET: Center for Hierarchical and Robust Modeling of Non-Equilibrium Transport
CHaRMNET: Center for Hierarchical and Robust Modeling of Non-Equilibrium Transport
Contact
COINFLIPS
COINFLIPS
Departments
Contact
Keywords:
- artificial intelligence
- neural networks
- neuromorphic
- probabilistic
- stochastic
Computing Platform Engineering (CPE) Initiative
Computing Platform Engineering (CPE) Initiative

The Computing Platform Engineering (CPE) Initiative, launched in FY25, aims to create a holistic and automated approach to accessing computing infrastructure, enhancing resource utilization, and informing strategic investments. It employs modern development methodologies to meet the demand for sustainable, purpose-built tools.
The project takes a cloud-like Platform Engineering approach and focuses on three main areas: Computing as a Service (CaaS), Platform Services, and Platform Interfaces. CaaS provides capabilities like an application programming interface (API), authentication, container orchestration, and intelligent routing. Platform Services will offer tools for container management and deployment of both services and web-based tools. Platform Interfaces emphasizes the sustainable development of custom web tools and digital thread integration.
The Advanced Simulation and Computing (ASC) User Experience (UX) team plays a crucial role in ensuring a user-centered approach across all areas. The project crosscuts many subprograms within the ASC Program, including a close collaboration with the Common Engineering Environment (CEE) and other enterprise-level projects to ensure common infrastructure support.
Contacts
E3SM – Energy Exascale Earth System Model
E3SM – Energy Exascale Earth System Model
E3SM is an unprecedented collaboration among seven National Laboratories, the National Center for Atmospheric Research, four academic institutions and one private-sector company to develop and apply the most complete leading-edge Earth system model to the most challenging and demanding subseasonal to decadal predictability imperatives. It is the only major national modeling project designed to address U.S. Department of Energy (DOE) mission needs and specifically targets DOE Leadership Computing Facility resources now and in the future, because DOE researchers do not have access to other major climate computing centers. A major motivation for the E3SM project is the coming paradigm shift in computing architectures and their related programming models as capability moves into the Exascale era. DOE, through its science programs and early adoption of new computing architectures, traditionally leads many scientific communities, including climate and Earth system simulation, through these disruptive changes in computing.
Engineering Common Model Framework (ECMF)
Engineering Common Model Framework (ECMF)
The Engineering Common Model Framework (ECMF) project aims to establish a unified platform for curating and continuously testing computational models, particularly those maintained as workflows at Sandia National Laboratories. Similar to existing frameworks at NNSA’s physics laboratories, ECMF seeks to provide a suite of perpetually maintained computational models that serve as a foundation for new analyses and are regularly assessed for improvements. However, the complexity and diversity of Sandia’s models necessitate analysts with specialized knowledge capable of creating intricate workflows.
By properly archiving and maintaining models, Sandia enhances its surveillance, assessment, and strategic functions for years to come, and ECMF’s goal is to build such capabilities in conjunction with Digital Engineering, Computing as a Service, and Computing Platform Engineering efforts.
FASTMath
FASTMath
The FASTMath SciDAC Institute develops and deploys scalable mathematical algorithms and software tools for reliable simulation of complex physical phenomena and collaborates with application scientists to ensure the usefulness and applicability of FASTMath technologies.
FASTMath is a collaboration between Argonne National Laboratory, Lawrence Berkeley National Laboratory, Lawrence Livermore National Laboratory, Massachusetts Institute of Technology, Rensselaer Polytechnic Institute, Sandia National Laboratories, Southern Methodist University, and University of Southern California. Dr. Esmond Ng, LBNL, leads the FASTMath project.
Contact
HPC Resource Allocation
HPC Resource Allocation
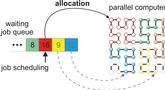
HPC resource allocation consists of a pipeline of methods by which distributed-memory work is assigned to distributed-memory resources to complete that work. This pipeline spans both system and application level software. At the system level, it consists of scheduling and allocation. At the application level, broadly speaking, it consists of discretization (meshing), partitioning, and task mapping. Scheduling, given requests for resources and available resources, decides which request will be assigned resources next or when a request will be assigned resources. When a request is granted, allocation decides which specific resources will be assigned to that request. For the application, HPC resource allocation begins with the discretization and partitioning of the work into a distributed-memory model and ends with the task mapping that matches the allocated resources to the partitioned work. Additionally, network architecture and routing have a strong impact on HPC resource allocation. Each of these problems is solved independently and makes assumptions about how the other problems are solved. We have worked in all of these areas and have recently begun work to combine some of them, in particular allocation and task mapping. We have used analysis, simulation, and real system experiments in this work. Techniques specific to any particular application have not been considered in this work.
Institute for the Design of Advanced Energy Systems (IDAES)
Institute for the Design of Advanced Energy Systems (IDAES)
Transforming and decarbonizing the world’s energy systems to make them environmentally sustainable while maintaining high reliability and low cost is a task that requires the very best computational and simulation capabilities to examine a complete range of technology options, ensure that the best choices are made, and to support their rapid and effective implementation.
The Institute for Design of Advanced Energy Systems (IDAES) was originated to bring the most advanced modeling and optimization capabilities to these challenges. The resulting IDAES integrated platform utilizes the most advanced computational algorithms to enable the design and optimization of complex, interacting energy and process systems from individual plant components to the entire electrical grid.
IDAES is led by the National Energy Technology Laboratory (NETL) with participants from Lawrence Berkeley National Laboratory (LBNL), Sandia National Laboratories (SNL), Carnegie-Mellon University, West Virginia University, University of Notre Dame, and Georgia Institute of Technology.
The IDAES leadership team is:
- David C. Miller, Technical Director
- Anthony Burgard, NETL PI
- Deb Agarwal, LBNL PI
- John Siirola, SNL PI
Contact
Kokkos
Kokkos
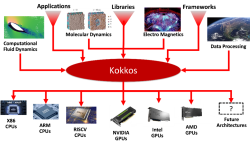
Modern high-performance computing (HPC) architectures have diverse and heterogeneous types of execution and memory resources. For applications and domain-specific libraries/languages to scale, port, and perform well on these architectures, their algorithms must be re-engineered for thread scalability and performance portability. The Kokkos programming system enables HPC applications and domain libraries to be implemented only once, while being performance portable across diverse architectures such as multicore CPUs, GPUs, and APUs.
This research, development, and deployment project advances the Kokkos programming system with new intra-node parallel algorithm abstractions, implements these abstractions in the Kokkos library, and supports applications’ and domain libraries’ effective use of Kokkos through consulting and tutorials. Kokkos is an open-source project in the Linux Foundation, with the primary development support coming from Sandia National Laboratories, Oak Ridge National Laboratory, and the French Alternative Energies and Atomic Energy Commission.
Mesquite
Mesquite
MESQUITE is a linkable software library that applies a variety of node-movement algorithms to improve the quality and/or adapt a given mesh. Mesquite uses advanced smoothing and optimization to:
- Untangle meshes,
- Provide local size control,
- Improve angles, orthogonality, and skew,
- Increase minimum edge-lengths for increased time-steps,
- Improve mesh smoothness,
- Perform anisotropic smoothing,
- Improve surface meshes, adapt to surface curvature,
- Improve hybrid meshes (including pyramids & wedges),
- Smooth meshes with hanging nodes,
- Maintain quality of moving and/or deforming meshes,
- Perform ALE rezoning,
- Improve mesh quality on and near boundaries,
- Improve transitions across internal boundaries,
- Align meshes with vector fields, and
- R-adapt meshes to solutions using error estimates.
Mesquite improves surface or volume meshes which are structured, unstructured, hybrid, or non-comformal. A variety of element types are permitted. Mesquite is designed to be as efficient as possible so that large meshes can be improved.
Departments
Contact
Neural Exploration & Research Lab (NERL)
Neural Exploration & Research Lab (NERL)

The SNL NERL facility enables researchers to explore the boundaries of neural computation. The research conducted in the lab evaluates what is possible with neural hardware and software for national security benefit and the advancement of basic research.
Current areas of NERL research include:
• Machine Learning and Deep Learning
• Microelectronics Co-Design
• Neural Computing and Applications to High Performance Computing (HPC)
• Computational and Mathematical Neuroscience
• Remote Sensing
• Edge Sensing and Processing
NERL includes a variety of neuromorphic hardware platforms that can be used for comparative benchmarking and architecture exploration. This neuromorphic research capability has enabled relationships with various academic institutions and industry partners that are designing and fabricating neuromorphic computing hardware.
NERL hardware includes:
• SpiNNaker
• Intel Loihi
To test new hardware, NERL relies on a suite of neural “mini apps” that assist researchers in understanding, predicting, and improving neuromorphic computing technologies. These Sandia-developed programs include neuromorphic random walks, neural sparse coding, and neural graph analysis.
Contact
Power API
Power API
Contact
Resilience Requirements for Exascale and Beyond
Resilience Requirements for Exascale and Beyond
Research shows that failures in current computer systems are common and are expected to increase in the future. This rise in failures is largely due to future systems having significantly more memory (like DRAM and SRAM) and more complex processing units (such as GPGPUs and FPGAs). To manage these failures, systems must incorporate recovery mechanisms. The unique scale and specific demands of high-performance computing (HPC) systems make this particularly challenging. Understanding both current and future workloads and hardware is essential to evaluate the effectiveness of existing recovery techniques and their suitability for future systems.
Reliability is especially critical as we transition beyond traditional computing in the post-Moore’s law era. Emerging technologies like quantum and neuromorphic computing may provide the necessary performance for next-generation workloads but also introduce uncertainties regarding reliability and accuracy.
This project aims to define the reliability requirements for current and future large-scale systems. By building on previous studies of failures and workloads in leading systems and utilizing a failure data repository, we will assess the reliability of current HPC hardware and identify potential failure-prone areas in future systems.
Our ongoing efforts will continue to focus on guiding reliability practices for exascale systems, influencing new programming models, and expanding our failure data repository for emerging computing technologies.
Contact
Stitch – IO Library for highly localized simulations
Stitch – IO Library for highly localized simulations
IO libraries typically focus on writing the entire simulation domain for each output. For many computation classes, this is the correct choice. However, there are some cases where this approach is wasteful in time and space.
The Stitch library was developed initially for use with the SPPARKS kinetic monte carlo simulation to handle IO tasks for a welding simulation. This simulation type has a particular feature where there is computational intensity in a small part of the simulation domain with the rest being idle. Given this intensity, only writing the area that changes is far more space efficient than writing the entire simulation domain for each output. Further, the computation can be focused strictly on the area where the data will change rather than the whole domain. This can yield a reduction from 1024 to 16 processes and 1/64th the data written. These combined can lead to a reduction in the computation time with no loss in data quality. If anything, by reducing the amount written each time, more output is possible.
This approach is also applicable for finite element codes that share the same localized physics.
The code is in the final stages of copyright review and will be released on github.com. A work in progress paper was presented at PDSW-DISCS @ SC18 and a full CS conference paper is planned for H1 2019 and a follow-on materials science journal paper.
Progressive data storage IO library. This library enables computing on a small part of the simulation domain at a time and then stitching together a coherent domain view based on a time epoch on request. Initial demonstration is for metal additive manufacturing. Paper at IPDPS 2020: DOI: 10.1109/IPDPS47924.2020.00016
Contact
Structural Simulation Toolkit (SST)
Structural Simulation Toolkit (SST)
The Structural Simulation Toolkit (SST) is a tool used to simulate large-scale and high-performance computing platforms. It allows users to design and test both the hardware (the physical parts of a computer) and software (the programs that run on the computer) together, seeing how they work with each other. This helps researchers understand and study new ideas in computer design. Design points such as instruction set architecture, memory systems, network interfaces, and the full system network can be studied together with programming models and algorithms.
SST has two differentiating features. First, it is designed to be modular which enables mixing and matching a variety of simulation models. This allows users to change and test specific parts of the system more easily. Second, it runs simulations in parallel, using common techniques including message passing (MPI) and threading. This makes it very efficient for simulating large and complicated systems. SST has been successfully used to study various concepts, including advanced memory processing and traditional processors that connect through high-speed networks.
Trilinos
Trilinos
Research Area
Contact
Vanguard
Vanguard

The Vanguard project is expanding the high-performance computing ecosystem by evaluating and accelerating the development of emerging technologies in order to increase their viability for future large-scale production platforms. The goal of the project is to reduce the risk in deploying unproven technologies by identifying gaps in the hardware and software ecosystem and making focused investments to address them. The approach is to make early investments that identify the essential capabilities needed to move technologies from small-scale testbed to large-scale production use.
Research Area
Contact
Zoltan
Zoltan
The Zoltan project focuses on parallel algorithms for parallel combinatorial scientific computing, including partitioning, load balancing, task placement, graph coloring, matrix ordering, distributed data directories, and unstructured communication plans.
The Zoltan toolkit is an open-source library of MPI-based distributed memory algorithms. It includes geometric and hypergraph partitioners, global graph coloring, distributed data directories using rendezvous algorithms, primitives to simplify data movement and unstructured communication, and interfaces to the ParMETIS, Scotch and PaToH partitioning libraries. It is written in C and can be used as a stand-alone library.
The Zoltan2 toolkit is the next-generation toolkit for multicore architectures. It includes MPI+OpenMP algorithms for geometric partitioning, architecture-aware task placement, and local matrix ordering. It is written in templated C++ and is tightly integrated with the Trilinos toolkit.