The transformative effect of GPUs and highly parallel communication
Graphics processing units are accelerating scientific applications central to Sandia’s mission through the advancement of artificial intelligence and machine learning. GPUs improve these applications by providing hardware support for mathematical operations ubiquitous in AI/ML and scientific computing. Specifically, GPUs target operations that can be computed in parallel—dividing a larger problem into sub-problems, each of which can be solved independently by a dedicated worker. The results of these independent computations are then combined to arrive at a solution to the larger problem.
This divide-and-conquer parallelism occurs at multiple scales in a typical scientific application: A very large problem that cannot be solved on a single computer is divided into sub-problems, each assigned to a computer, or node, in a networked cluster. In addition to one or more traditional central processing units, each node in the cluster may have one or more GPUs. The portion of the problem assigned to the node may be further split into even smaller sub-problems to execute on GPUs using millions of distinct workers.
Because different nodes host different sub-problems, which often depend on calculations from other sub-problems, the nodes must exchange data with each other at certain times. For instance, a simulation of a body of water may divide a problem spatially, with each node responsible for some cube of liquid. The nodes communicate with each other to propagate interactions between spatially adjacent cubes located on different computers. The standard for this communication between processes in HPC is called Message Passing Interface.
Conceptually, MPI is straightforward: To send data from program A running one process to program B running another process, process A puts the data in an ‘envelope’ — a message header with routing and data placement information — addresses it to process B, and sends it. Like the post office, the MPI implementation takes care of locating the destination and ensuring the data gets there.
However, MPI can encounter obstacles when GPUs compute data in parallel. Firstly, when multiple workers are involved with sending data, successful communication depends upon the efforts of each individual worker. If one worker is delayed, all communication is delayed until the last worker is done. Even if the data is ready, it will not be sent until the last worker is finished.
Secondly, while GPUs accelerate the computation of certain types of operations, it can come at the cost of sacrificing performance of others. Traditionally, GPUs are not efficient at MPI message processing. Due to GPU ineffiencies, CPUs on a node must be responsible for the communication between nodes. This creates additional overhead because data must move from GPU to CPU memory before transmission.
Sandia’s innovation: using partitioned communication to accelerate GPU-initiated communication
To facilitate a solution to these challenges, Sandia has pioneered an approach to inter-process communication known as Partitioned Communication. Two features of PartComm help address these complications. First, PartComm allows a message to be split into partitions, each of which can be sent independently of one another. Under PartComm data communication no longer has to remain hostage to a lagging worker. This ability to communicate earlier is termed “earlybird” communication.
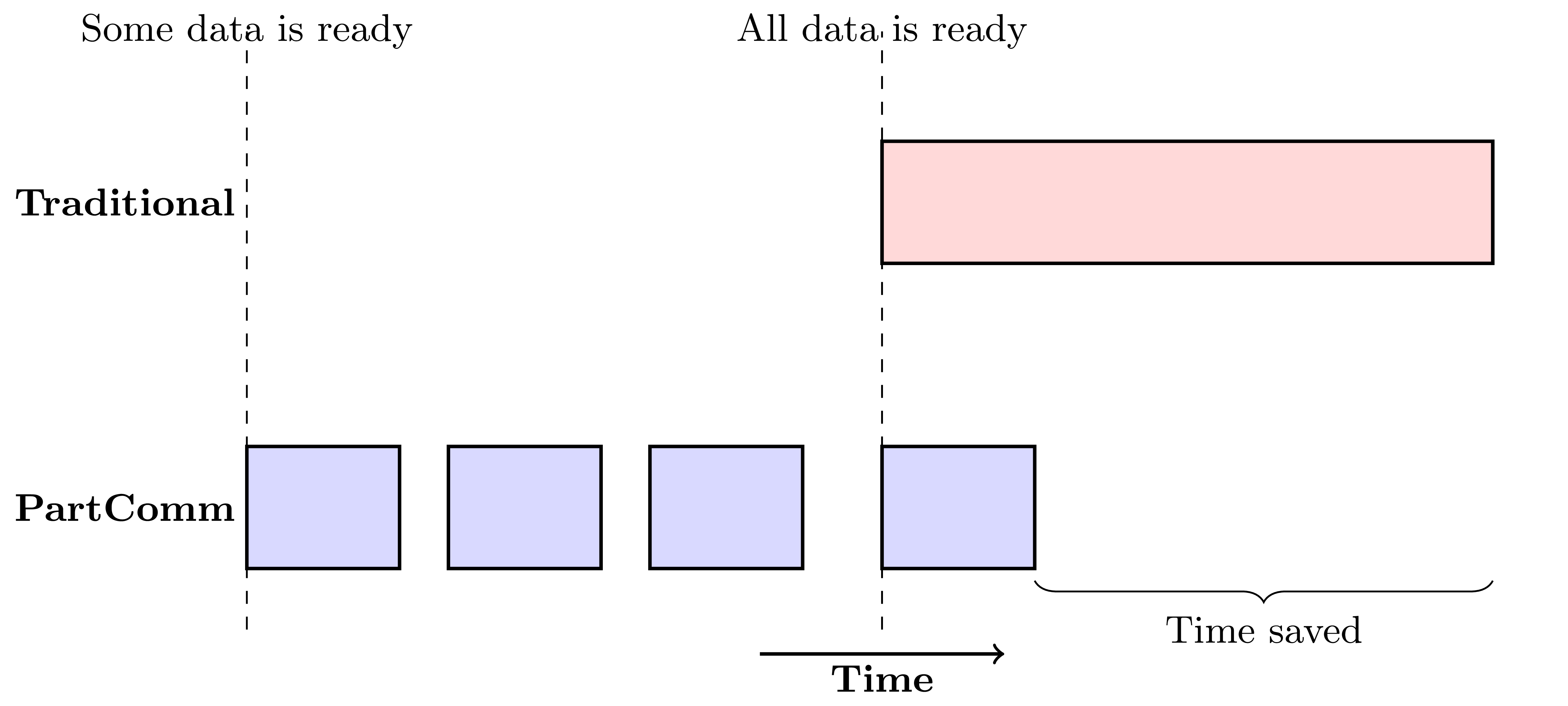
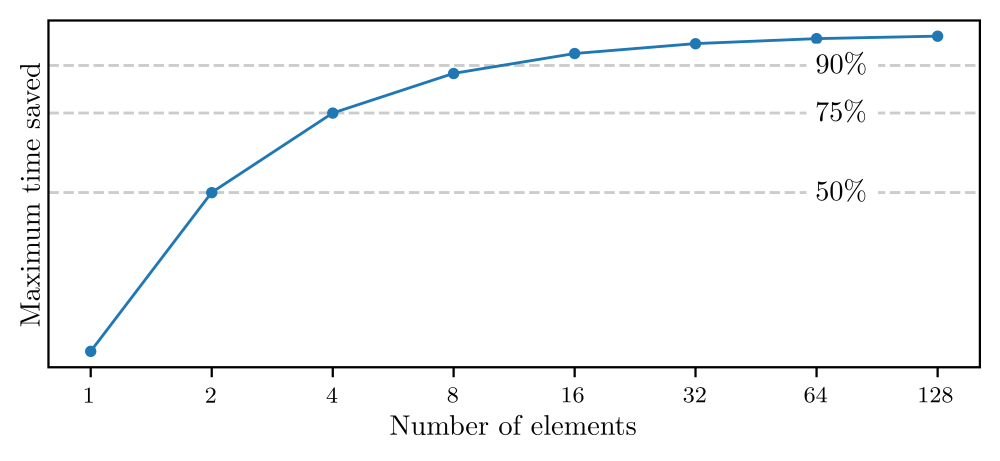
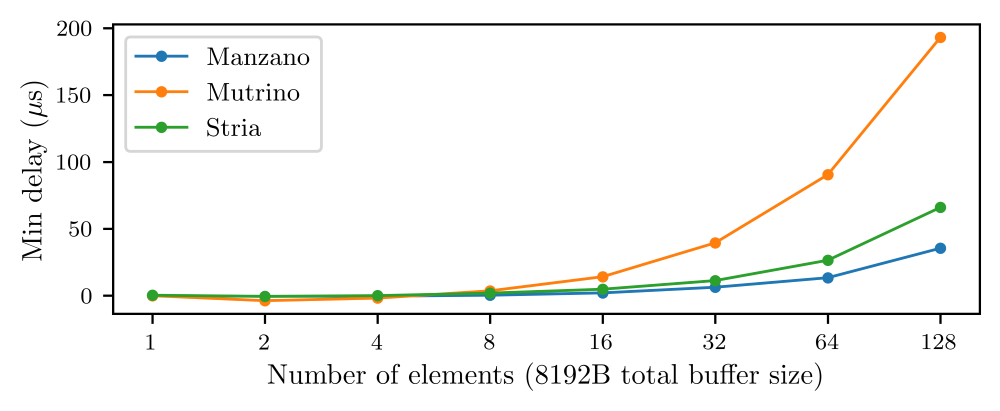
In a series of modeling and benchmark studies, Sandia researchers explored the potential benefits of earlybird communication and the conditions under which those benefits accrue. The researchers established a principle of diminishing returns for earlybird communication. For example, the study found that under ideal circumstances, only eight partitions were needed to save 90% of data transfer time compared to traditional communication. Researchers used an empirically informed model to estimate how far behind, in microseconds, a lagging worker would need to be before seeing a benefit from earlybird communication as the number of partitions increase. In collaboration with Queen’s University, Sandia implemented a library targeting cutting-edge network technology for optimizing PartComm by dynamically adjusting the number of partitions used based on this model.
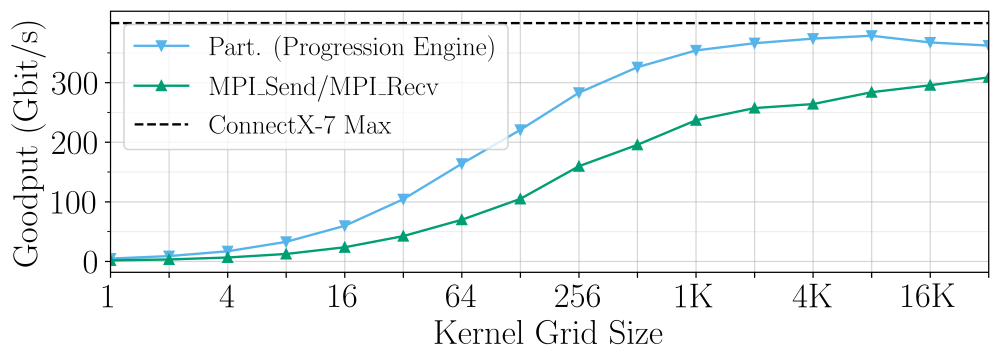
The second innovation of PartComm is a lightweight mechanism for initiating data transfer suitable for GPU use. Whereas traditional message transfer requires that the sender package and address the data to be sent every time data needs to be moved, PartComm establishes a single communication channel that can be reused multiple times. Once a partition is complete, a worker can use the GPU to ‘trigger’ the pre-defined data movement, such as flipping a bit or setting a flag. This contrasts with alternative point-to-point communication methods in MPI, which requires extra logic to perform message processing every time communication is initiated. This often requires large amounts of branching that reduce GPU performance through warp divergence. PartComm has the added benefit of dovetailing with emerging network technology explicitly designed to support these types of operations. The library Sandia developed with its academic partners enables GPU-initiated PartComm capable of outperforming traditional MPI by 2.8 times for certain grid sizes.
This ability to bypass traditional MPI and the added benefits of earlybird communication will help Sandia move beyond the infrastructure constraints that have traditionally limited the use of GPU communication. PartComm provides Sandia with the unique opportunity to advance GPU communication in exploring future application designs within HPC.