A federated-learning model prototype to enhance national security efforts

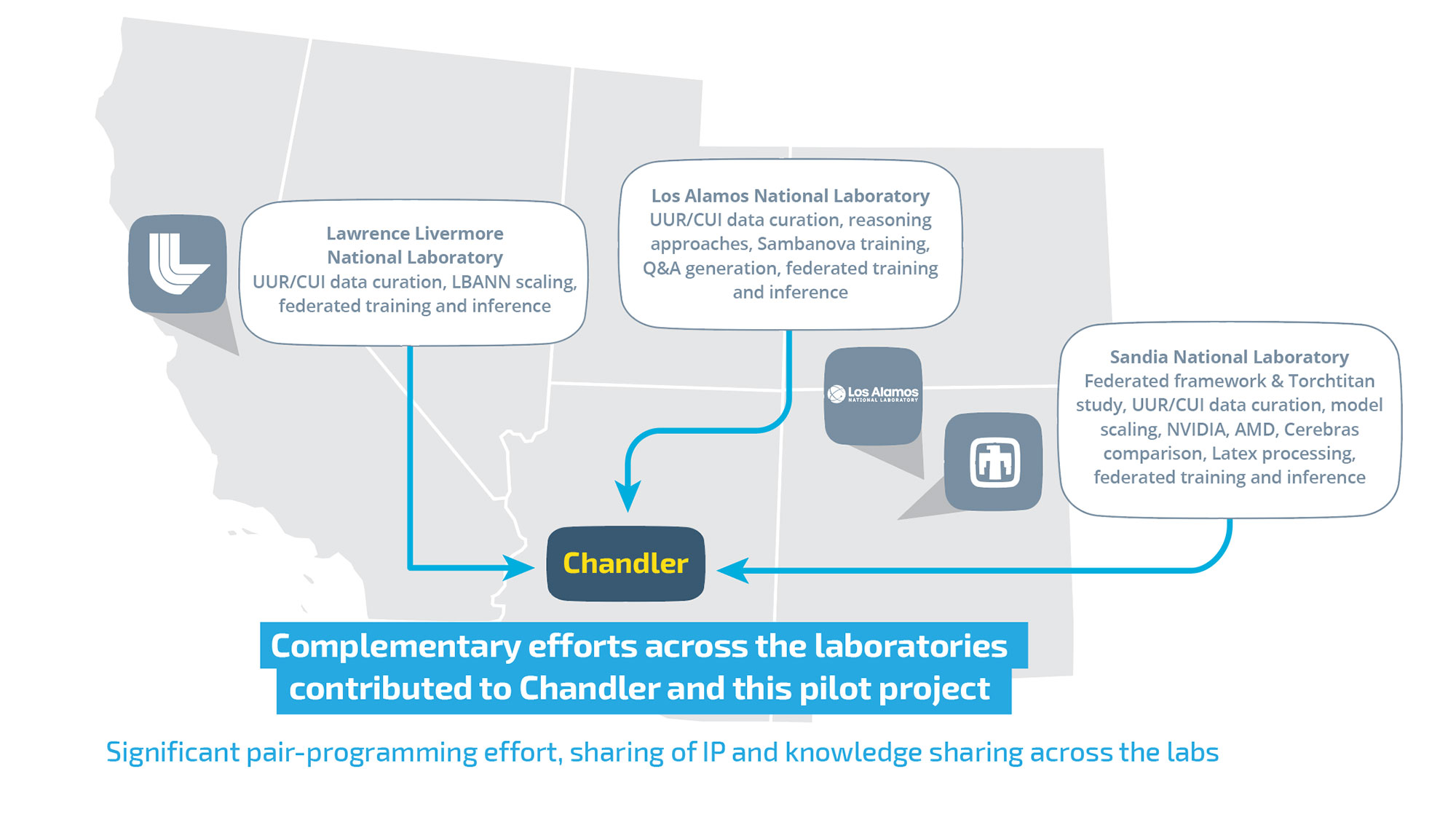
A significant milestone has been not only accomplished but exceeded in the effort to advance artificial intelligence for national security. Over the past year, Sandia, Los Alamos and Lawrence Livermore national laboratories — known as the trilabs — have been building a federated-AI model as a pilot project, and they now have a prototype. Federated learning is a technique for training AI models on decentralized data.
Led by Sandia and funded through the NNSA’s Advanced Simulation and Computing program, the project started with a high-risk but high-reward goal of training a large, federated AI model across the trilabs.
“In order to make AI tools more accurate and more applicable to our national security mission, NNSA is going to need an enduring capability to train, and consistently retrain, AI models with our classified datasets,” said Si Hammond, program director of advanced computing in the NNSA Office of Advanced Simulation and Computing. “Federated training is a critical tool to delivering a robust capability in a cost effective, performant and secure way.”
Building AI models while safeguarding sensitive data
Each of the trilabs possesses unique datasets that are not easily shareable, yet they hold valuable insights for collaboration in critical mission areas. “Commercial large language models often fall short in their response to NNSA mission-relevant queries,” said Siva Rajamanickam, distinguished member of Sandia’s technical staff and the project’s lead. “Due to the inaccessibility of this specialized data within NNSA laboratories, the effectiveness of open-source or proprietary models is limited for our use cases.”
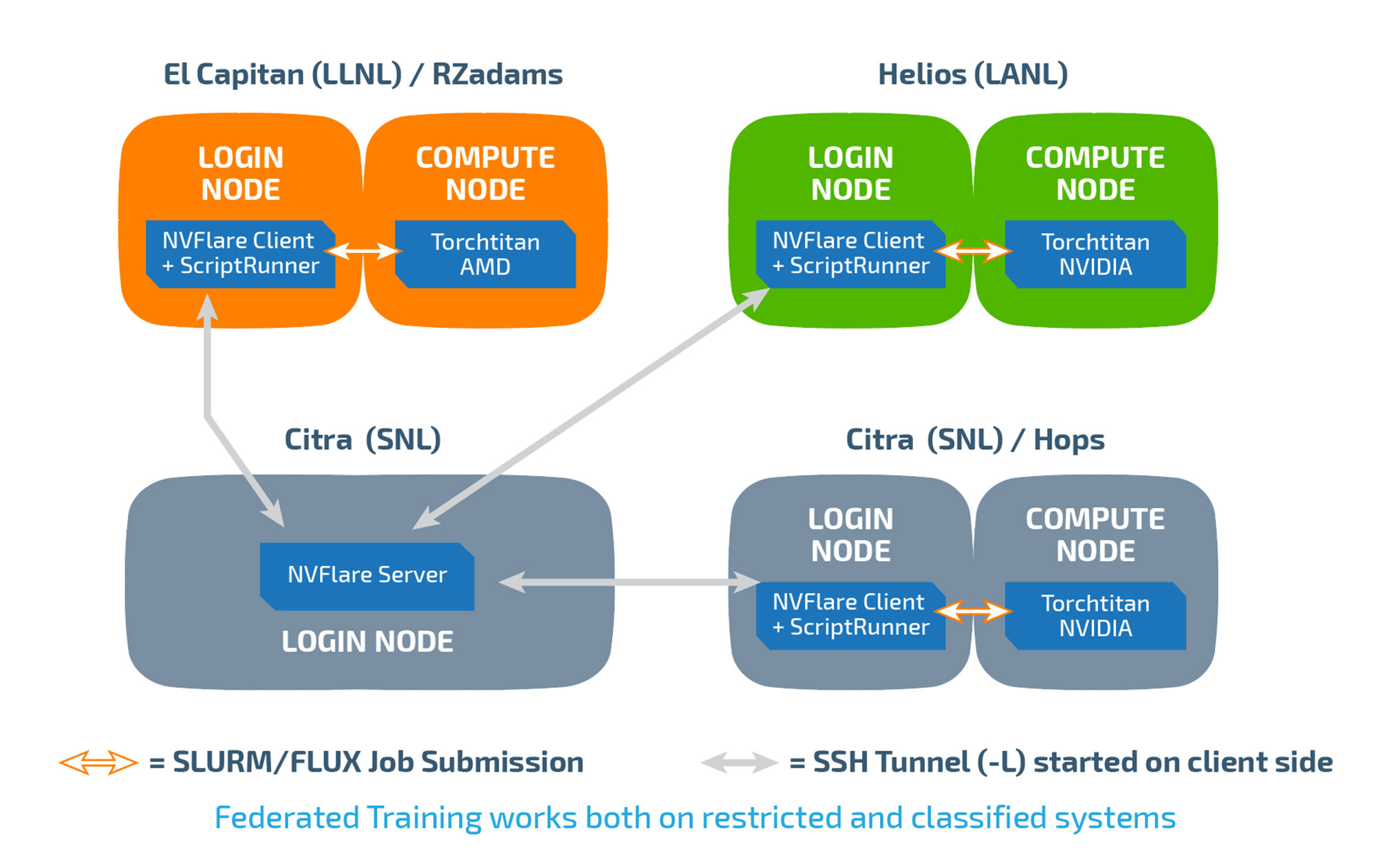
Despite the challenges of training a language model on three different, geographically distributed systems, the research team has successfully demonstrated a prototype that proves a shared model is possible while protecting each laboratory’s unique data. Through the federated-learning approach, the trilabs have proven that they can collaboratively train the model by sharing only the “weights,” or the parameters that represent the model’s learning, without explicitly exchanging the datasets themselves.
The project used NVIDIA’s NVFlare, an open-source federated-learning software, to orchestrate the training process. At each phase, or epoch, of the training process, the software exchanges the updated weights, but not the data, between the three labs to allow them to be averaged together to form a single model. This updated set of weights is then sent to the other labs for the next epoch of training to begin.
“The labs coordinated on the processing of data to ensure that (it) was available in the format that the local training software, Meta’s open-source Torchtitan library, could handle,” said Chris Siefert, principal member of the technical staff at Sandia. “Sandia and Lawrence Livermore researchers demonstrated that Torchtitan can scale well on both NVIDIA and AMD GPU hardware, including results on Livermore’s El Capitan, the world’s fastest supercomputer.”
Early collaboration enables future success
A memorandum of understanding among the Advanced Simulation and Computing executives at the three laboratories enabled the sharing of model weights. Jen Gaudioso, director of the ASC program at Sandia, said, “By putting our data management and weight-transfer protocols into a single memorandum of understanding, Sandia, LANL and LLNL laid the foundation for an agile federated-learning ecosystem that will drive next-generation mission outcomes.”
Sandia has a strong team in AI research. Interest in this project was a natural extension of efforts like the BANYAN Institute for Generative AI, which unites AI initiatives across the labs by sharing datasets, models, software stacks, expertise and industry collaborations.
This federated-learning project is just the beginning. Research will continue into how the model can be improved and expanded while ensuring that it will not memorize or replicate the shared data but still understand it.