Description
This page provides an alternative catalog for a subset of the UUEB catalog provided by semi-supervised learning experiments using the Sandia developed Shadow python library. The catalog contains 7878 events, 10 less than the full UUEB catalog. This alternate release does not include accelerometer or infrasound stations and was made for the purpose of augmenting the original catalog with data-driven predictions using semi-supervised learning.
The additional table is avaliable in .csv format with the following nomenclature:
SSML UUEB Catalog Field Descriptions
| Field Name | Description | Example |
|---|---|---|
| evid | Event ID | 990 |
| sta | SEED station name | ROA |
| shadow_assigned_label | Labeling scheme used in baseline/SSML experiments. unlabeled > no assigned label mie > Mine Induced Earthquake qb > Quarry Blast le > Local Earthquake | le |
| baseline_waveform_level_prediction | Baseline experiment label prediction for the individual waveform. {mie, qb, le} | mie |
| eaat_waveform_level_prediction | SSML experiment label prediction for the individual waveform. {mie, qb, le} | mie |
| baseline_event_level_prediction | SSML experiment label prediction at the event level. {mie, qb, le} | le |
| eaat_event_level_prediction | SSMIL experiment label prediction at the event level. {mie, qb, le} | qb |
| etype | Event labeling based on NNSA KB Core schema. {me, qa, -, qp, ec, mp, qt, ep, ex, qf} This labeling has a many to one relationship with shadow_assigned_label {qt, qg, qa, qp} > le {ex, ep, ec} > qb {mp, me} > mie {-} > unlabeled |
Experiment Design
The UUEB catalog contains over 43,000 individual waveforms but over 4,000 do not have an associated event label. In an attempt to provide high quality labels to all events, we leveraged data driven nueral network models to predict labels for all waveforms. We’ve designed two prediction pipelines that we call the baseline (supervised) and semi-supervised machine learning (SSML) experiments to produce the labels.
In the baseline experiment, we first filter out UUEB catalog data that has a source-reciever distance greater than 200km. We’ve found that waveforms greater than 200km exibit poor prediction performance in our models. This is followed by splitting the leftover data (~39000 waveforms) into 5 subsets, each containing a disjoint set of event IDs while maintaining an equal representation of event classes relative to the full data set. Each subset includes a proportional amount of unlabeled data. We then performed extensive hyperparameter optimization using 5-fold cross validation with a supervised VGG-like model. Using the selected hyperparameters we train a model on a permutation of 4 subsets, and predict on the held out fold regardless of the ‘shadow_assigned_label’. Repeating for each permutation, we then aggregate model predictions for all 39,000 waveforms. In this way, each waveform appears once in the test set and the provided label predictions are for samples never previously seen by the model. In the alternative catalog, these predictions are under the ‘baseline_waveform_level_prediction’ column. Likewise, under the ‘baseline_event_level_prediction’ column we provide predictions using the mode of the baseline_waveform_level_prediction for each event ID. Under this experiment design, our baseline models performed relatively well, achieving < .1% error using event level aggregation.
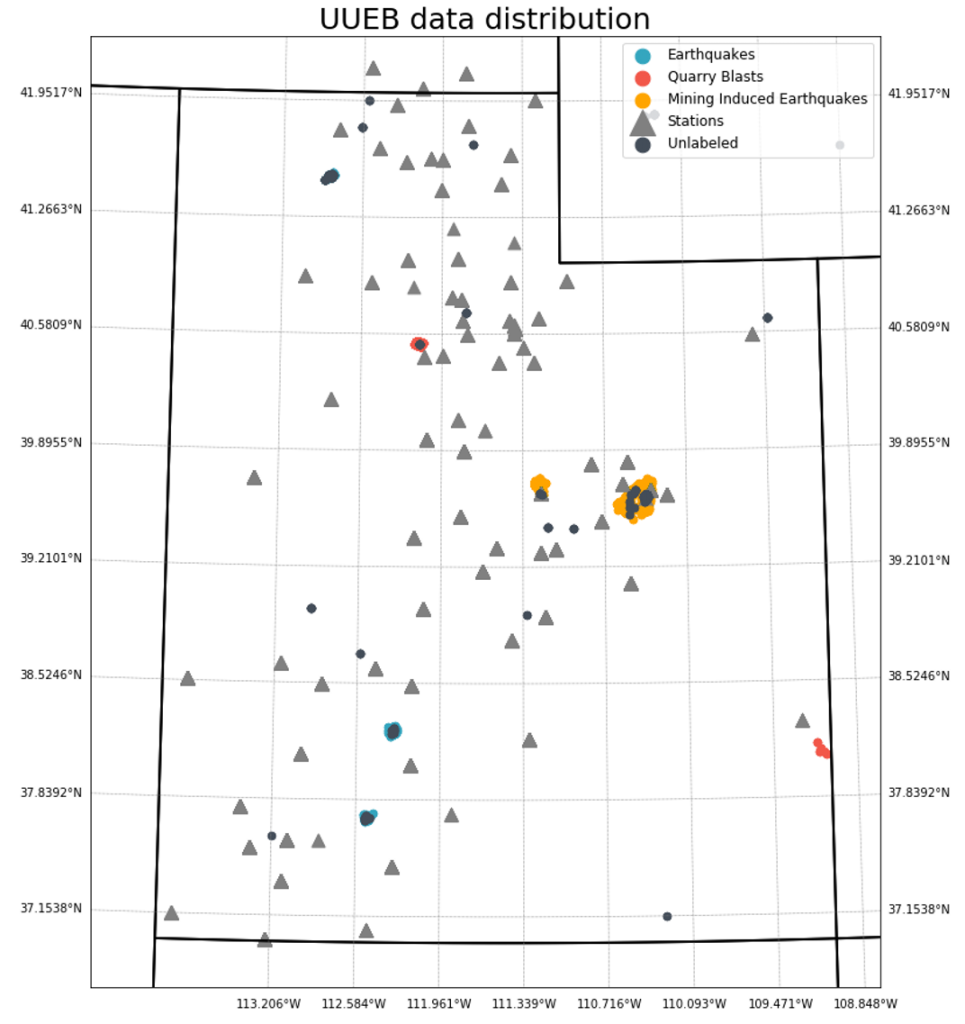
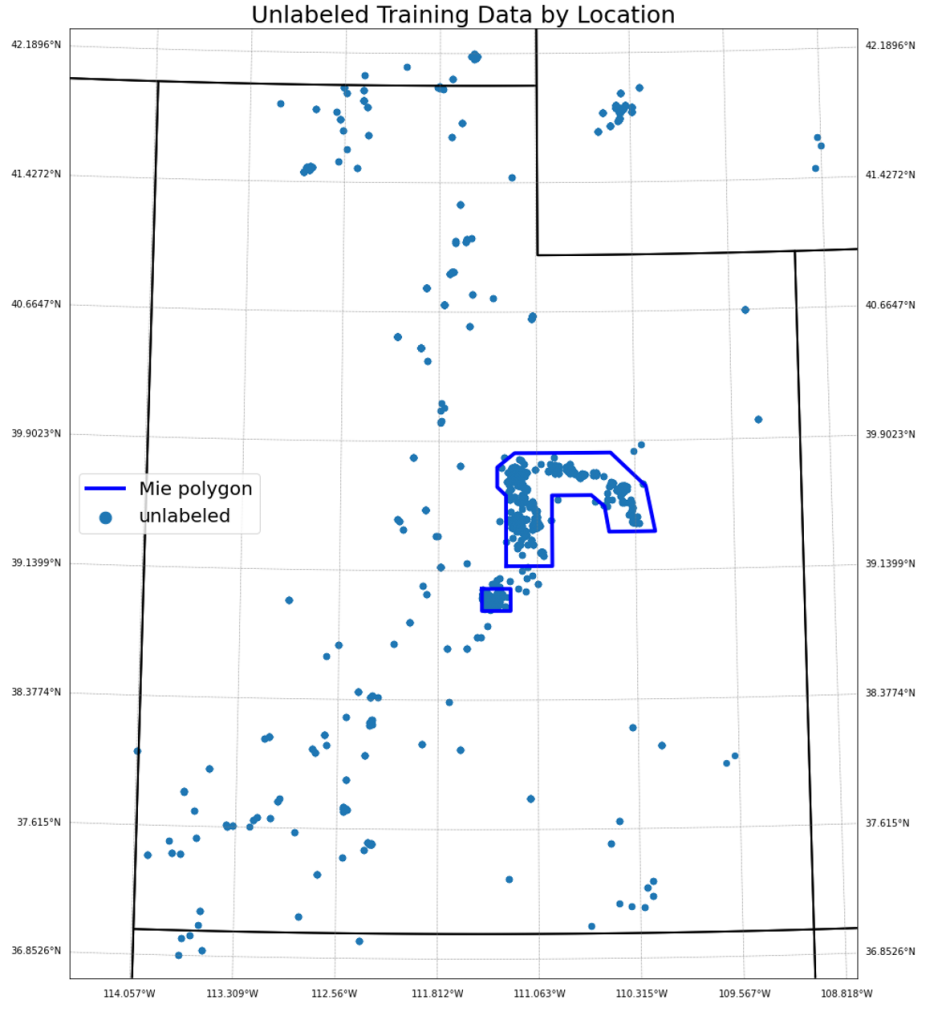
On top of the low error rates in the baseline experiment, we sought to further address one of the drawbacks of the UUEB catalog, namely the sparse geographical distribution of event regions and the lack of event type diversity within each region. This can be seen in the distribution of labeled and unlabeled events in the UUEB data distribution figure above. In order to promote greater geographical and event type uniformity, we augmented the UUEB data with unlabeled data from existing catalogs in Utah (Linville et al., 2019; catalog download) called the UUSS catalog. The geographical distribution of additional UUSS data can be seen in the figure below. We then perform SSML experiments in a similar fashion to baseline experiments. UUSS data is divided into 5 subsets, each containing a disjoint set of event IDs. Subsequently, each UUSS subset is concatenated to the associated UUEB subset. The rest of the experiment design is equivalent to the baseline except we use the Exponentiated Average Adversarial Training (EAAT) technique provided by Shadow for all training. EAAT allows trained models to take advantage of the increase in geographical uniformity in the training set, with the goal of increased model performance. Similarly to baseline, we provide waveform and event level predictions from the EAAT model in the alternative catalog.
Our experiments ultimately found that SSML models performed within a statistical margin of the baseline (supervised) model. In most cases the baseline and SSML model predictions agree with eachother, while the small subset of disagreements (36 events) were primarily driven by resolving of ties and high uncertainty. This is consistent with our general observation that semi-supervised learning offers less value when supervised models are already high-performing and unlabeled data quantity does not significantly outweigh labeled data.