The goal of the Aeras LDRD project is to develop a next-generation atmosphere model suitable for a global climate model, with advanced capabilities such as performance portability and embedded uncertainty quantification (UQ). Performance portability will allow us to run our code very efficiently on a diverse set of current and future computer architectures (such as GPUs or threaded CPUs) without a laborious porting process. Our particular approach to embedded UQ takes advantage of running ensembles of simulations to achieve speedups.
Recently, we completed initial development of the 3D hydrostatic equations, which are the target equations for the atmosphere in climate, and a hyperviscosity implementation, which is the preferred method for stabilizing our spectral element discretization. These implementations are currently undergoing rigorous and methodical testing.
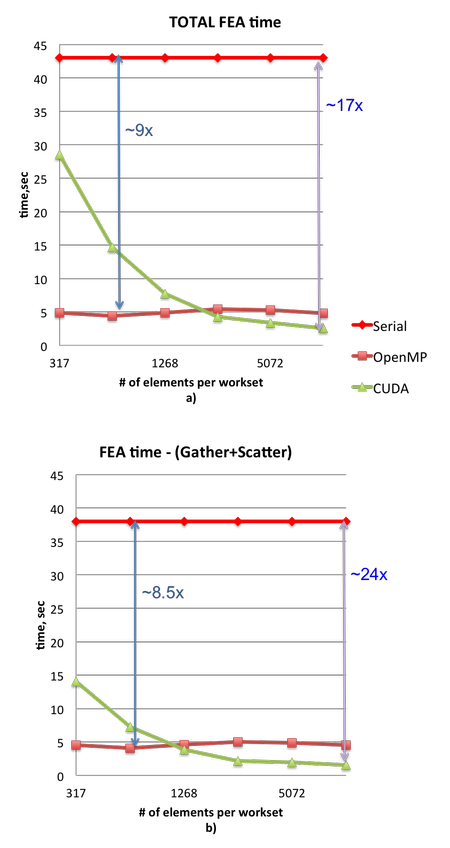
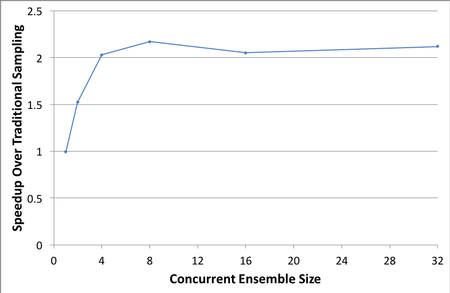
The 2D shallow water equations (applied to air, not water) for the global atmosphere were implemented previously and have already demonstrated the project’s next-generation capabilities. We see a roughly 9 times performance increase using threaded CPUs and up to 24 times performance increase with GPUs when the amount of computational work is sufficient. Our approach for computing ensemble samples concurrently can add up to 2 times performance increase when running as few as four samples concurrently. We expect to see similar results for 3D when the hydrostatic equations are ready for performance analysis.