A Sandia team is performing computer simulations for nuclear deterrence missions 10 to 20 times faster after making a series of improvements, ultimately enabling them to produce better information about how a nuclear weapon will function in various environments and wear throughout its lifetime.
Sandia researchers have been actively developing a massively parallel structural dynamics finite element code, called Sierra Structural Dynamics, or SD, for more than 25 years. The code is used for system-level analyses and design of nuclear weapons and is part of the Sierra Engineering Mechanics code suite for mechanical, fluid and thermal modeling. During the last several years, the team made software and hardware updates to speed up performance.
Code developers integrated the latest graphical processing units, or GPUs, and updated default code parameters so that users would not need to make modifications to the simulation files to run simulations on machines with or without GPUs.
As a primarily linear code, a majority of the runtime in structural dynamics analyses are in the linear system solves and dense matrix computations. The GPU is well suited for these types of computations.
Developers enabled computation on the GPU by using other code packages developed at Sandia, including Trilinos, Kokkos and Tacho. The team used packages in Trilinos that implement GPU-ready operations via Kokkos, and the sparse-direct linear solvers provided by Tacho helped improve GPU performance.
Most of SD’s performance-critical operations are now built upon Trilinos objects. Through the sustainable component architecture, most of the GPU-related complexity and maintenance are hidden from the SD application. This approach to central processing unit, or CPU, GPU portability allows developers to focus on the big picture as they work to expand GPU support to SD algorithms and will be the approach used to migrate to next generation machines moving forward.

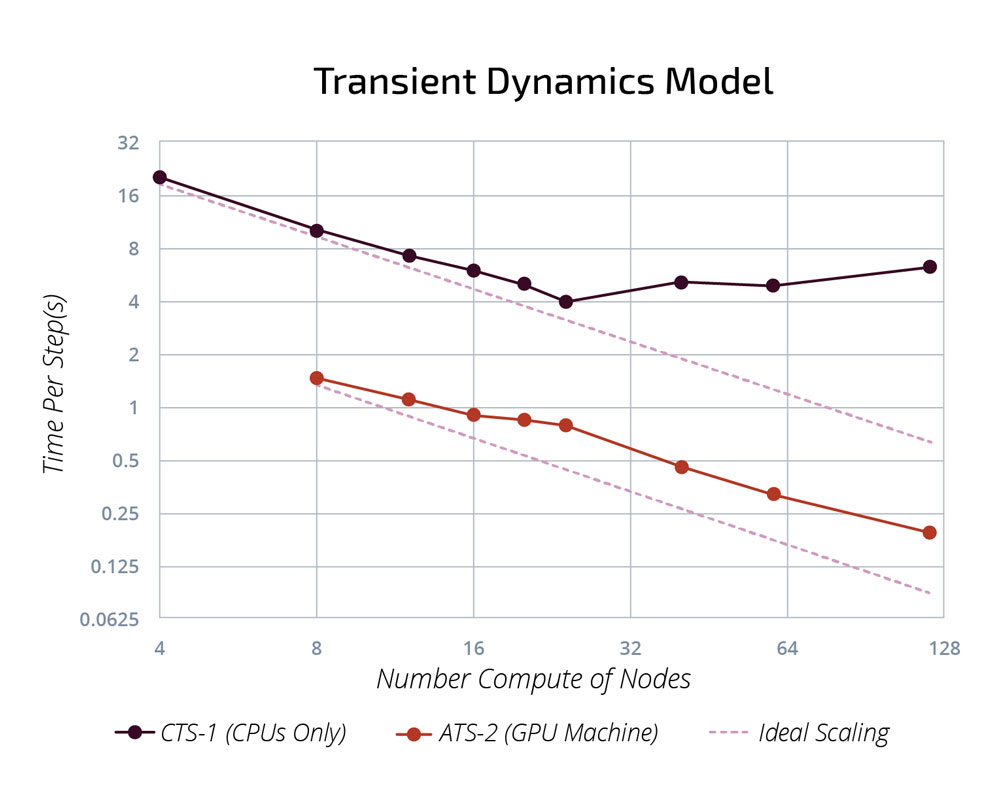
Along with algorithmic optimizations, better use of memory on the GPU platforms also provided better scalability. In a strong scaling study performed for a transient dynamics acceptance test model, the time per time step for the CPU-only machine CTS-1 begins to plateau after approximately 24 compute nodes while that for the GPU-based machine ATS-2 continues to scale up to 128 compute nodes.
Additionally, analysts used Lawrence Livermore National Laboratory’s new advanced high performance computing system Sierra, known as ATS-2, to run simulations. ATS-2 offers immense throughput performance and scalability. The faster runtimes and shorter queues have enabled more analyses within a typical project timeline, higher fidelity simulations and routine heroic simulations.
Enhance Existing Analyses: Component model updating
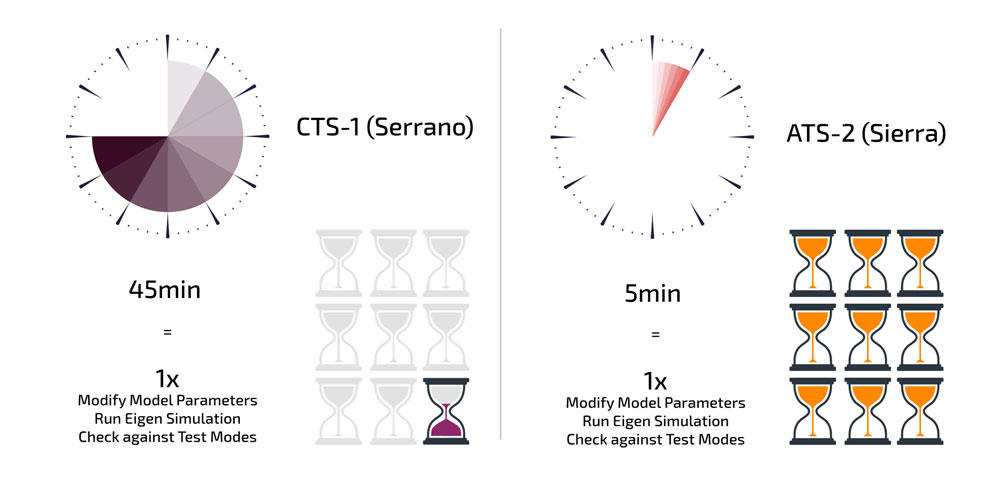
The performance improvements in SD have enhanced existing analyses by improving turnaround times for model calibration. In one example, an analyst iteratively performed eigen simulations to calibrate model parameters until frequencies and mode shapes match between test measurements and simulation. Each iteration on the CTS-1 required 45 minutes to perform the modification of parameters, run the simulation, and compare results to measurements. Using the GPU-based machine ATS-2, the analyst was able to complete each iteration in five minutes. The speedups provided closer to real-time feedback about parameter changes and more freedom to see what happens with each iteration.
High Fidelity Experimental Test Support
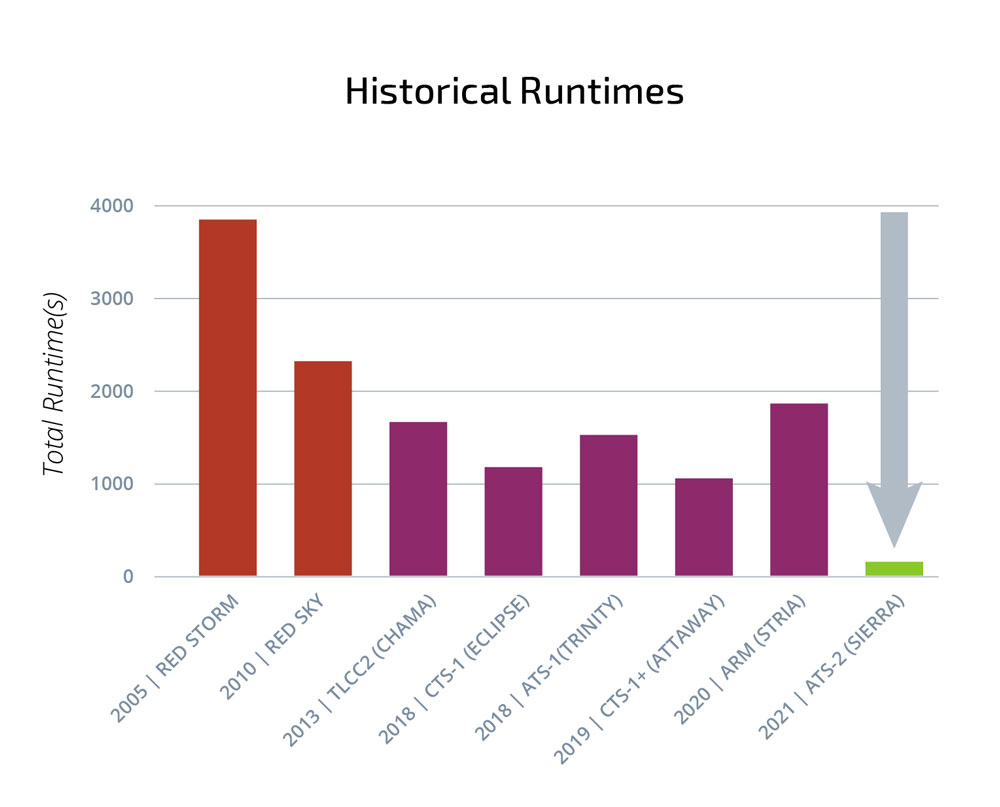
Analysts often work to support experimental design through simulations. In this second example, an analyst performed system model simulations to inform the design of an Impedance-match multi-axis test. IMMAT testing is used to represent the response of a structure to complex vibration loads by attaching multiple shakers to excite the structure at discrete measurement points. Simulations can help determine the location of the shakers to produce representative response in the structure. Simulation speedups from 20 hours on legacy machines to three hours using ATS-2 resulted in an approximately one-week turnaround from request to results. Such completion times were previously unobtainable in support of experimental test design.
Routine “Heroic” Simulations
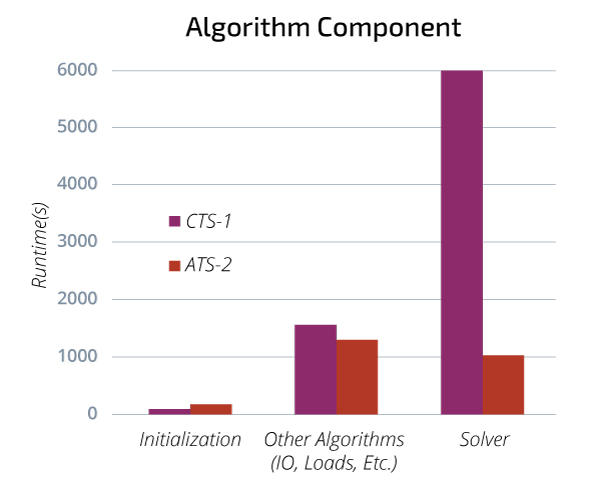
Heroic simulations are long, complex, high-fidelity simulations that are rarely run. For example, a high-fidelity, full-system model may need to be simulated when sub-component analyses raise questions about the full-system response. When such simulations are attempted on legacy machines, the run could take weeks to complete due to queue times and the need to perform restarts. Access to ATS-2 has enabled high-fidelity, full-system dynamics to be simulated in as little as 10 hours. Routine “heroic” simulations can now be performed overnight. The ability to perform heroic simulations and produce conclusive results overnight allows analysts to provide better information to customers, resulting in more informed decision making.