This section explains what the PHISH software package is and why we created it. It outlines the steps to creating your own PHISH program, and gives a simple example of using PHISH to perform a parallel calculation. These are the topics discussed:
Informatics is data-driven computing and is becoming more prevalent, even on large-scale parallel machines traditionally used to run scientific simulations. It can involve processing large archives of stored data or data that arrives on-the-fly in real time. The latter is often referred to as "streaming" data. Common attributes of streaming data are that it arrives continuously in a never-ending stream, its fast incoming rate requires it be processed as it arrives which may limit the computational effort per datum that can be expended, and its high volume means it cannot be stored permanently so that individual datums are examined and discarded.
A powerful paradigm for processing streaming data is to use a collection of programs, running as independent processes, connected together in a specified communication topology. Each process receives datums continuously, either from the stream itself, or read from a file, or sent to it from other processes. It performs calculations on each datum and may choose to store "state" internally about the stream it has seen thus far. It can send the datum on to one or more other processes, either as-is or in an altered form.
In this model, a data-processing algorithm can be expressed by choosing a set of processes (programs) and connecting them together in an appropriate fashion. If written flexibly. individual programs can be re-used in different algorithms.
PHISH is a small software package to make the task of designing and developing such algorithms easier, and allowing the resulting program to be run in parallel, either on distributed memory platforms that support MPI message passing, or on a collection of computers that support socket connections between them.
PHISH stands for Parallel Harness for Informatic Stream Hashing.
Here is what these words mean, in the PHISH context. "Parallelism" can be achieved by using multiple copies of processes, each working on a part of the stream, or by using the memory of multiple processes to store state about the stream of data. It is a framework or "harness" for connecting processes in a variety of simple, yet powerful, ways that enable parallel data processing. While it is designed with "streaming" "informatics" data in mind, it can also be used to process archived data from files or in a general sense to perform a computation in stages, using internally generated data of any type or size. "Hashing" refers to sending datums to specific target processes based on the result of a hash operation, which is one means of achieving parallelism.
It is important to note that PHISH does not replace or even automate the task of writing code for the individual programs needed to process data, or of designing an appropriate parallel algorithm to perform a desired computation. It is simply a library that processes can call to exchange datums with other processes, and a setup tool that converts an input script into a runnable program that can be easily launched in parallel.
Our goal in developing PHISH was to make it easier to process data, particularly streaming data, in parallel, on distributed-memory or geographically-distributed platforms. And to provide a framework to quickly experiment with parallel informatics algorithms, either for streaming or archived data. Our own interest is in graph algorithms but various kinds of statistical, data mining, machine learning, and anomaly detection algorithms can be formulated for streaming data, in the context of the model described above. We hope PHISH can be a useful tool in those settings as well.
The name PHISH was also chosen because it evokes the image of fish (programs) swimming in a stream (of data). This unavoidably gives rise to the following PHISH lingo, which we use without apology throughout the rest of the documentation:
The model described above is not unique to PHISH. Many programs provide a framework for enabling data to flow between computational tasks interconnected by "pipes" in a dataflow kind of paradigm. Visualization programs often use this model to process data and provide a GUI framework for building a processing pipeline by connecting the outputs of each computational node to the inputs of others. The open source Titan package, built on top of VTK, is one example, which provides a rich suite of computation methods, both for visualization and data processing. The commercial InfoSpheres tool from IBM uses a similar dataflow model, and is designed for processing streaming data at high rates. Twitter recently released an open-source package called "Twitter Storm" which has been advertised as Hadoop for streaming data, since it enables streaming MapReduce-style computations and runs with fault-tolerance on top of a parallel file system like HDFS. PHISH has many conceptual similarities to Storm, though PHISH has fewer features, such as no support for fault tolerance.
Dataflow frameworks like these are often designed to run as a single process or in parallel on a shared memory machine. The computational nodes in the processing pipeline are functions called as needed by a master process, or launched as threads running in parallel.
By contrast, PHISH minnows (computational nodes in the processing pipeline), are independent processes and the PHISH library moves data between them via "messages" which requires copying the data, either using the MPI message-passing library or sockets. This allows PHISH programs to be run on a broader range of hardware, notably distributed-memory parallel platforms, but also incurs a higher overhead for moving data from process to process.
The following list highlights additional PHISH pheatures:
The PHISH package contains a library and a tool for defining and running PHISH nets. These are the steps typically used to perform a calculation, assuming you have designed an algorithm that can be encoded as a series of computational tasks, interconnected by moving data between them.
Step (1): An overview of the PHISH library and instructions for building it are given in this section.
Step (2): A minnow is a stand-alone program which makes calls to the PHISH library. An overview of minnows, their code structure, and how to build them, is given in this section. The API for the PHISH library is given in this section, with links to a doc page for each function in the library.
Step (3): The syntax and meaning of commands used in PHISH input scripts are described in this section.
Step (4): The bait.py tool, its command-line options, and instructions on how to use it, are described in this section. Before using it the first time, one or more backend libraries must be built, which are in the src directory. This can be done as part of step (1).
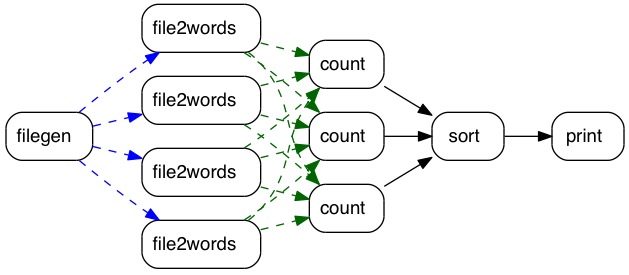
The steps outlined in the preceding section are somewhat abstract. Here is a concrete example of using a PHISH program to count the number of times different words appear in a corpus of text files. This is effectively a MapReduce operation, where individual minnow processes perform the map() and reduce() functions. This is a diagram of how 5 different kinds of minnows can be connected together to perform the computation:
Code for all 5 of these minnows is in the example directory of the PHISH distribution, both in C++ and Python. The filegen minnow takes a list of files and/or directories as user input, searches them recursively, and generates a series of filenames. The filenames are sent one-at-a-time to one of several file2words minnows. Each receives a filename as input, opens and reads the content, and parses it into words. Each word is hashed and sent to a specific count minnow, as indicated by the all-to-all green arrows. The key point is that each count minnow will receive all occurrences of a subset of possible words. It uses an internal hash table to count the occurrences of each word it receives. Note that parallelism is enabled by invoking multiple copies of the file2words and count minnows.
When the filegen minnow sends the last filename, it sends a "done" message to each of the file2words minnows. When they receive a "done" message, they in turn send a "done" message to each count minnow. When a count minnow has received a "done" message from all the file2words minnows, it sends its entire list of unique words and associated counts to the sort minnow, followed by a "done" message. When the sort minnow has received "done" message from all the upstream count minnows, it knows it has received all the unique words in the corpus of documents, and the count for each one. It sorts the list by count and sends the top N to the print minnow, followed by a "done" message. N is a user-defined parameter. The print minnow echoes each datum it receives to the screen or a file, until if receives a "done" message. At this point all minnows in the school have been shut down.
More details about this example are discussed in subsequent sections of the manual:
Note that like a MapReduce, the PHISH program runs in parallel, since there can be N file2words minnows and M count minnows where N >= 1, M >= 1, and N = M is not required. This is similar to the option in Hadoop to vary the numbers of mappers and reducers.
However, there are also some differences between how this PHISH program works as compared to a traditional MapReduce, e.g. as typically performed via Hadoop or the MapReduce-MPI library.
In a traditional MapReduce, the "map" stage (performed by the file2words minnows) creates a huge list of all the words, including duplicates, found in the corpus of documents, which is stored internally (in memory or on disk) until the "mapper" process is finished with all the files it processes. Each mapper then sends chunks of the list to each "reduce" process (performed by the count minnows). This is the "shuffle" phase of a Hadoop MapReduce. The reducer performs a merge sort of all the words in the chunks it receives (one from each mapper). It can then calculate the count for each unique word.
In contrast, the PHISH program operates in a more fine-grainded fashion, streaming the data (words in this case) through the minnows, without ever storing the full data set. Only a small list of unique words is stored (by the count minnows), each with a running counter. PHISH exchanges data between minnows via many tiny messages (one word per message), whereas a traditional MapReduce would aggregate the data into a few large messages.
This is a simplistic explanation; a fuller description is more complex. Hadoop, for example, can operate in streaming mode for some forms of MapReduce operations, which include this wordcount example (MapReduce operations where the "reducer" needs all data associated with a key at one time, are not typically amenable to a streaming mode of operation.) The PHISH minnows used in this school could be modified so as to aggregate data into larger and fewer messages. Likewise, in a traditional MapReduce, large intermediate data sets can be stored out-of-core. PHISH does have the capability to do that unless a minnow is written that writes information to disk and retrieves it.
However the fundamental attributes of the PHISH program are important to understand. Data moves continuously, in small chunks, through a school of minnows. Each minnow may store "state" information about the data it has previously seen, but typically not all the data itself. "State" is typically limited to information that can be stored in-memory, not on disk. This is because for streaming data, too much data arrives too quickly, for a minnow to perform much computation before discarding it or sending it on to another minnow.
Here is a diagram of a variant of the wordcount operation that illustrates how PHISH can be used to process continuous, streaming data. The PHISH program in this case might run for days or weeks, without using the "done" messages described above.
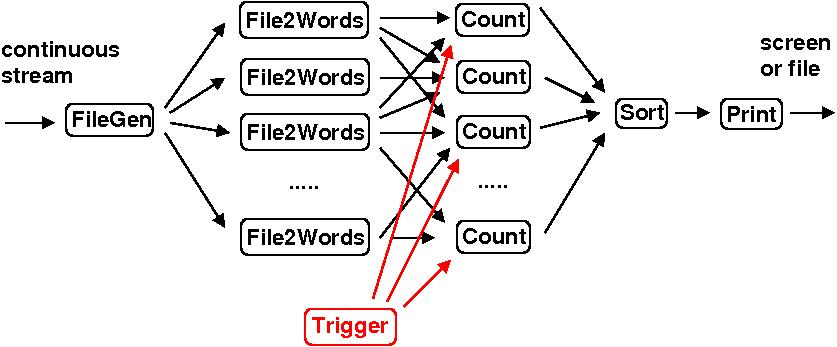
In this case the filegen minnow is continuously seeing new files appear in directories it monitors. The words in those files are processed as they appear. A Trigger minnow has been added which accepts user queries, e.g. via a keyboard or a socket connection. When the user makes a request (hits a key), a message is sent to each of the count minnows on a different input port than it receives words from the file2words minnows; see this section of the PHISH Minnows doc page for a discussion of ports. The message triggers the count minnows to send their current unique word/count list to the sort minnow which is sorted and printed via the print minnow.
The PHISH job now runs continuously and a user can query the current top N words as often as desired. The filegen, count, and sort minnows would have to be modified, but only in small ways, to work in this mode. Additional logic could be added (e.g. another user request) to re-initialize counts or accumulate counts in a time-windowed fashion.
PHISH development has been funded by the US Department of Energy (DOE), through its LDRD program at Sandia National Laboratories.
The following paper describes the basic ideas in PHISH. If you use PHISH in your published work, please cite this paper and include a pointer to the PHISH WWW Site (http://www.sandia.gov/~sjplimp/phish.html):
S. J. Plimpton and T. Shead, "Streaming data analytics via message passing with application to graph algorithms", submitted to J Parallel and Distributed Compuing, 2012.
PHISH was developed by the following individuals at Sandia:
PHISH comes with no warranty of any kind. As each source file states in its header, it is a copyrighted code that is distributed free-of- charge, under the terms of the Berkeley Softward Distribution (BSD) License.
Source code for PHISH is freely available for download from the PHISH web site and is licensed under the modified Berkeley Software Distribution (BSD) License. This basically means it can be used by anyone for any purpose. See the LICENSE file provided with the distribution for more details.