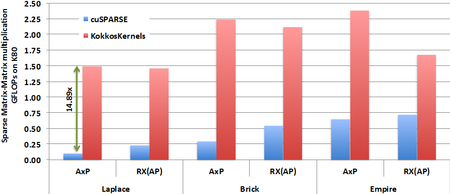
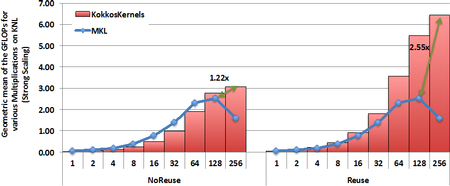
Sandia researchers developed a new algorithm for a performance-portable sparse matrix-matrix multiplication kernel in the KokkosKernels package. This new kernel is thread scalable, and memory-efficient in comparison to other publicly available implementations. It also optimizes for use cases from Sandia applications, such as reusing the symbolic structure of the problems for applications especially when the setup phase of multigrid methods is repeated more than once. The new Kokkos based implementation enables performance portability in GPUs, CPUs and Intel Xeon Phis. Currently the KokkosKernels SPGEMM routine is up to ~14.89x (5.39x on average) faster than NVIDIA’s cuSPARSE library routine on K80 GPUs. It also achieves 1.22x speedups (geometric mean) w.r.t. Intel’s MKL library routine on Intel’s Knights Landing (KNL). When the kernel can reuse the symbolic structure in multigrid multiplications it is 2.55x faster than Intel MKL library on Intel’s KNL. The memory-efficient algorithm also allows solving larger problems that cannot be solved by codes like NVIDIA’s CUSP library and Intel’s MKL when using larger number of threads.